
Inside Slope's Agents Platform for Credit Risk & Customer Operations

Slowly, Then All at Once
At Slope, we power embedded capital programs for some of the largest platforms in the world (Amazon, Walmart, Alibaba, IKEA, Samsung), handling everything from customer onboarding (KYB/KYC) to underwriting, monitoring, and servicing SMBs with a team of just 23.
When coding agents started transforming how our engineering team worked, the contrast with the operations side was difficult to ignore. It was clear that models could finally handle complex multi-step workflows, and we had teams that needed it.
In engineering, we were quickly adopting tools like Cursor's coding agent to help speed up initial feature development and address pull request feedback automatically. This has improved the quality of our product and unlocked new levels of productivity.
Our risk and support teams, however, were still spending hours compiling credit memos and triangulating across tools to answer a single ticket. Growth was still writing one-off queries to pull partner data.
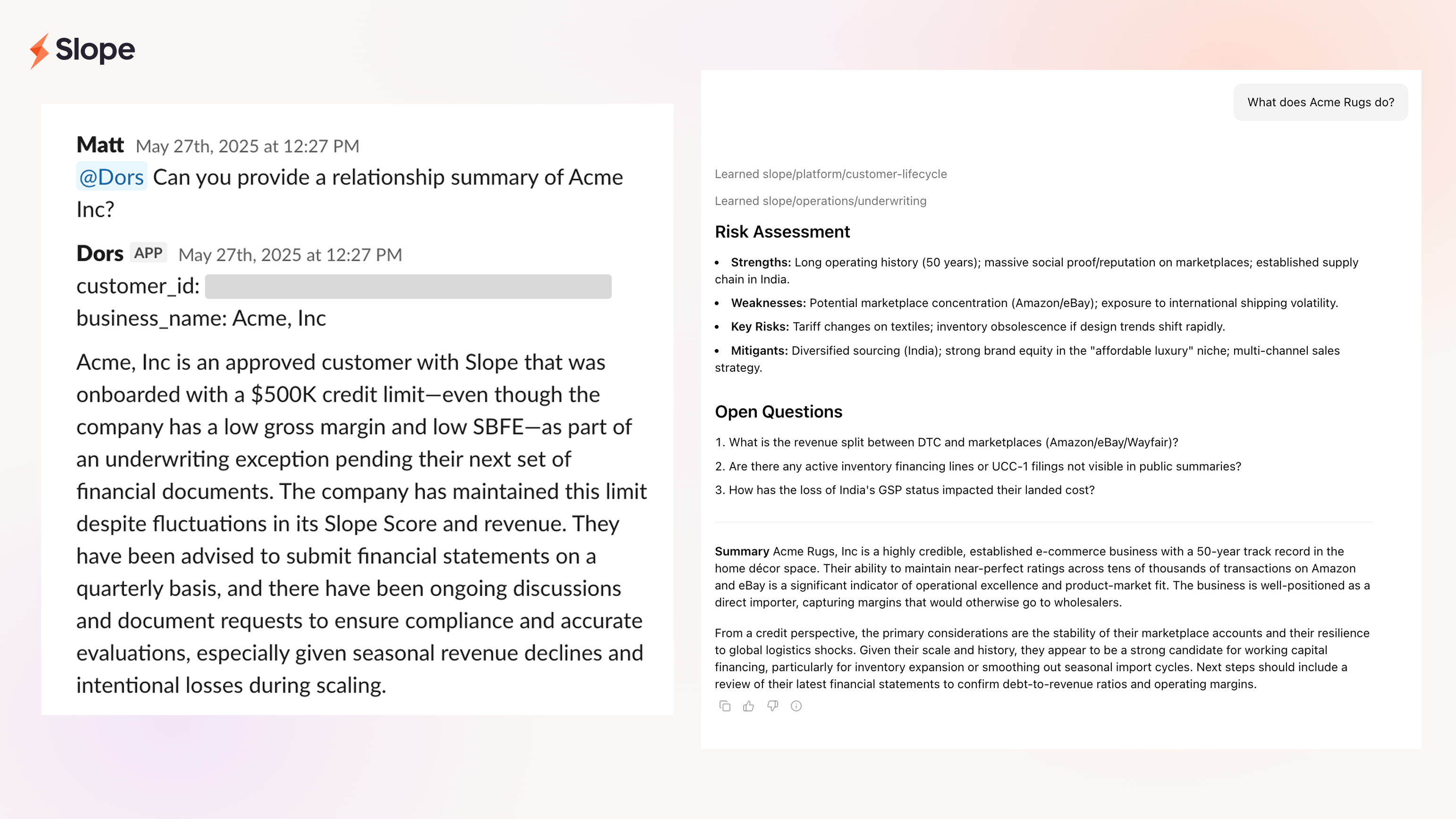
We've tried taking a stab at this problem previously. First with DeepKYB, an LLM-based crawler that compiled public data on customers for KYB/KYC. Then with Dors, a Slack-based chatbot the risk team used for underwriting questions such as "Why did Slope score decrease in May for Acme Inc?" Both proved the demand but neither had the level of sophistication that agents are capable of today:
- DeepKYB could only see what was public and had no access to our internal systems.
- Dors was a single LLM request with a limited, predefined set of data injected into the prompt. There was no ability to send follow-up messages or connect to other tools.
What we needed was a way to use agents to help us tackle and get ahead of even the most complex problems, connecting the dots across systems and tools, and synthesizing the many pieces into a coherent answer. Agents that run analyses in the background while teams work on other things. Agents that surface context before anyone has to ask.
Agent response truncated for brevity. Displayed with sample data.
What We Built
We built an internal platform to define and deploy autonomous agents that are capable of handling our existing workflows and processes.
To give you a sense of the types of agents that have been built, we'll focus on three:
- a generalist the entire company utilizes
- a dedicated agent for credit and risk review
- a dedicated agent for customer support
Each was developed in close collaboration with the teams that use them, but more importantly, they don't rely on engineering to evolve. We built a lightweight agent builder that lets operational teams define prompts, iterate on knowledge, and update configurations directly.
That means Jeremy on support and Matt on risk don't need to file tickets or wait in a queue. They can open the builder, iterate, and ship improvements to their agents themselves.
Scout: The Generalist
Scout is the entry point. When someone needs to understand why a customer got a certain pricing tier, what originations looked like last month, or what happened in a specific partner launch, Scout is usually where they start.
Before Scout, answering these questions meant writing a query, cross-referencing Salesforce, scanning Slack, and assembling an answer by hand. That worked fine until partnerships increased and business applications multiplied.
Scout has access to a set of tools and the ability to invoke specialized agents for specific jobs:
- Data Analyst — knows our system of record, writes and runs SQL
- Salesforce Admin — fluent in our CRM: cases, accounts, contacts
- Web Analyst — web searching and external research
- Report Builder — PDF generation
Scout decides which combination to use based on the question. The user doesn't have to make that call. Lawrence, our CEO, uses it to pull originations reports broken down by partners. Growth uses it to slice pricing data. The questions vary but the workflow is the same – Scout breaks down the ask, picks the right tool or subagent, and assembles the answer.
Roughly 70% of what these agents do is data work, querying systems, staging results, running transformations, and assembling aggregates. The remaining 30% is research, drafting, and cross-referencing, and that ratio shaped how we built the tooling.
This is the leap from where Dors was. Instead of putting everything in the prompt and hoping, the agent figures out what it needs, goes and gets it, and brings it back in a structured form.
When the answer is quantitative, Scout doesn't just return text. The platform supports generative UI, a catalog of React components (bar charts, tables, cards) that agents can render by returning structured JSON artifacts. The agent decides what to visualize based on the data shape and the question. It's the difference between getting a number in a Slack message and getting a chart you can actually read.
Credit Review Agent: Consistency at Scale
This is the agent Matt on our risk team uses. Most underwriting decisions are fully automated through our underwriting system. But for a small percentage of applications, typically driven by higher risk profiles, larger transaction sizes, or edge cases, we require a human-in-the-loop review.
A credit memo is the internal document that lays out the rationale behind a lending decision. It pulls together a business's financials, risk signals, transaction behavior, and qualitative context to justify why we should approve (or decline) a customer, especially in cases where our automated system alone isn't permitted to make the call.
Producing a credit memo for a customer was incredibly manual. Someone on our risk team opens a dozen tabs, runs analytics queries, cross-references multiple internal tools, and spends hours stitching everything into a coherent narrative.
The credit review agent follows a template the risk team defines: what the memo should look like, which signals matter, how the output is structured. That template didn't appear overnight – it was years of figuring out how we best underwrite a customer. What signals do we need to turn around a decision in 24 to 48 hours for a very large business without digging into how they run their operations?
The finished memo is a detailed PDF document. Each section encodes judgment from years of real lending experience. A generic agent, given our data without our framework, wouldn't know what to look for. The moat isn't the model — it's the institutional knowledge the model is executing against. Everyone can flip the switch and upgrade to a better model, but not everyone has four years of underwriting decisions shaping what their agents look for.
The agent pulls from relevant systems (Salesforce, Slack, etc.), runs the analysis, and assembles the memo following the template. Matt reviews it, checking the signals, adjusting anything that doesn't fit. From there, the team makes the decision. The agent does the prep and our team does the decision making.
Customer Support: Closing the Response Gap
When a customer writes in, the question is usually simple: Why is something blocked? What's the status of my application? What are you waiting on?
But answering it isn't.
Someone on the team has to reconstruct what happened – checking product analytics in PostHog, pulling logs from Datadog, scanning exceptions in Sentry, querying the system of record for the latest status, and stitching it all together. It's no straight-forward process and can take upwards of 15 minutes just to gather enough context to draft a response.
To streamline this, we've built an agent with access to each of these tools. Instead of the team starting from scratch, the agent starts first by running its own investigation in the background and assembling the context before anyone even triages the support case. A lot of the time, it answers the question perfectly and if not, by the time the team begins triage, there's already an internal note of what happened, why it happened, and what matters.
Under the Hood
The platform was initially built around two principles we established early on:
- Agents observe, they don't act. Every interaction an agent has with our systems and tools is read-only. Agents cannot modify data or trigger side effects. They surface context and recommendations for humans to review and act on.
- Everything must be traceable. There should be no question how an agent came to a conclusion. Every step in the agent's execution should be recorded and every configuration change should be versioned.
Here's how we built the platform with those things in mind.
Agent definition
An agent's definition is fully declarative and versioned. Every change creates an immutable version. This is what makes traceability and quality control more manageable (more on that below).
The definition covers every aspect of an agent including:
- System prompt, model, and tools
- Sandbox environment including mounted files, preloaded builtins (eg; ripgrep), and network access
- Skills that can be discovered
- Skills are folders of instructions and resources that can be discovered in its sandbox environment by the agent during execution. We use them at Slope to share institutional knowledge (eg; how to interpret a credit signal, how to respond to a specific type of customer issue) without copying the information into the system prompt, ultimately causing context bloat.
- Memory namespaces it can read and write to, usually scoped to the thread, user, or entity (eg; customer, loan) in context
- Delegation rules including which agents it can delegate to and when it should delegate to them
- Compaction strategy such as how many recent turns to maintain
- Generative UI components it can choose to render
- Channels it can receive messages on such as Slack, email, or our in-app chat app
None of this requires engineering to change. We've partnered with owners on each team, Jeremy on support and Matt on risk, who review historical threads, adjust prompts, update skills, and publish improvements to their agents themselves.
The harness
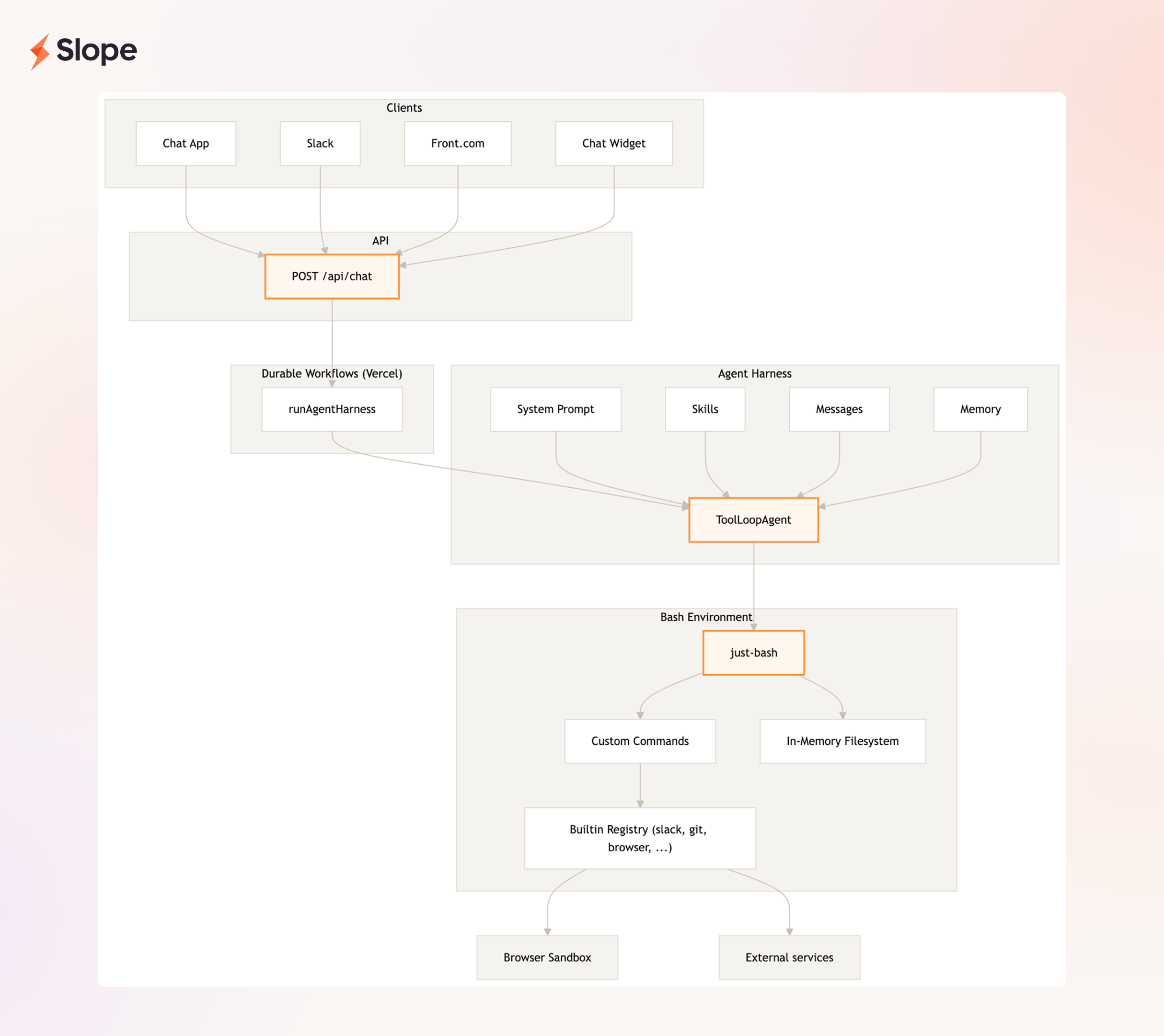
The agent definition is just one piece. Everything surrounding the model — tool execution, context management, compaction triggers, response streaming, guardrails, observability — is handled by what is called the harness. If the definition is the agent's DNA and the model is its brain, the harness is the nervous system. The same harness runs regardless of channel — Slack, in-app chat, and email all converge on the same harness with the same tools and the same traceability.
We considered wrapping something like OpenCode, but those frameworks are geared for coding agents. We built our own, it's a simple main loop (~800 lines). The interesting parts are how we handle reliability, isolation, and traceability.
Durable workflows
Every agent turn runs as a durable workflow (we use Vercel Workflow) so each step is independently checkpointed and retryable. For example, if a tool call fails mid-turn it is retried without restarting from the beginning, avoiding costly LLM calls. We also leverage durable workflows for:
- Background execution — agents run in the cloud, not in the user's browser. Start the credit memo agent, close your laptop, come back later and the result is waiting. Sessions can also be triggered automatically (when a customer email arrives the agent starts investigating before anyone reviews the ticket).
- Human-in-the-loop and timers — if the agent needs to wait for human input or sleep for a period of time, the workflow enters a paused state without consuming compute resources or losing its place. When the condition is met, it picks up exactly where it left off.
Sandbox
Each agent gets a sandbox: a virtualized workspace powered by just-bash with an in-memory file system, a curated set of builtins, and limited network access. The agent uses it the way an engineer would use a terminal to stage data, pipe outputs, and run transformations. The sandbox is configured per agent and persists across turns in the same thread.
When an agent needs more powerful tools (eg; a headless browser, a Jupyter server), the harness proxies the command to a remote virtual machine running that tool. Files are copied between the sandbox and remote machine as needed, so the agent operates as if everything is local.
Thread as a log
In most systems, a thread stores messages — what the user said, what the agent replied. Telemetry, cost tracking, and custom events live somewhere else.
We made a deliberate choice within our data model to capture as much of the execution record as possible within the thread. Messages, tool calls, token usage and costs, sandbox timing, compaction history, active agent versions, and more all live in the same place.
This means we don't run a separate observability stack. When Matt asks why a credit memo looks off, we pull up the thread in "debug mode" and walk through every step the agent took. When we need to understand cost, we simply sum cost metadata across messages so there’s no need to correlate with an external billing pipeline. The quality control system (below) scores threads by reading the same message data the user sees. Cost dashboards, quality control, and debugging all query the same source of truth.
Quality control
Last, but definitely not least, we built an internal quality control system to help us identify gaps and quickly iterate on the agent definition and skills. There's three components: datasets, scoring, and actions.
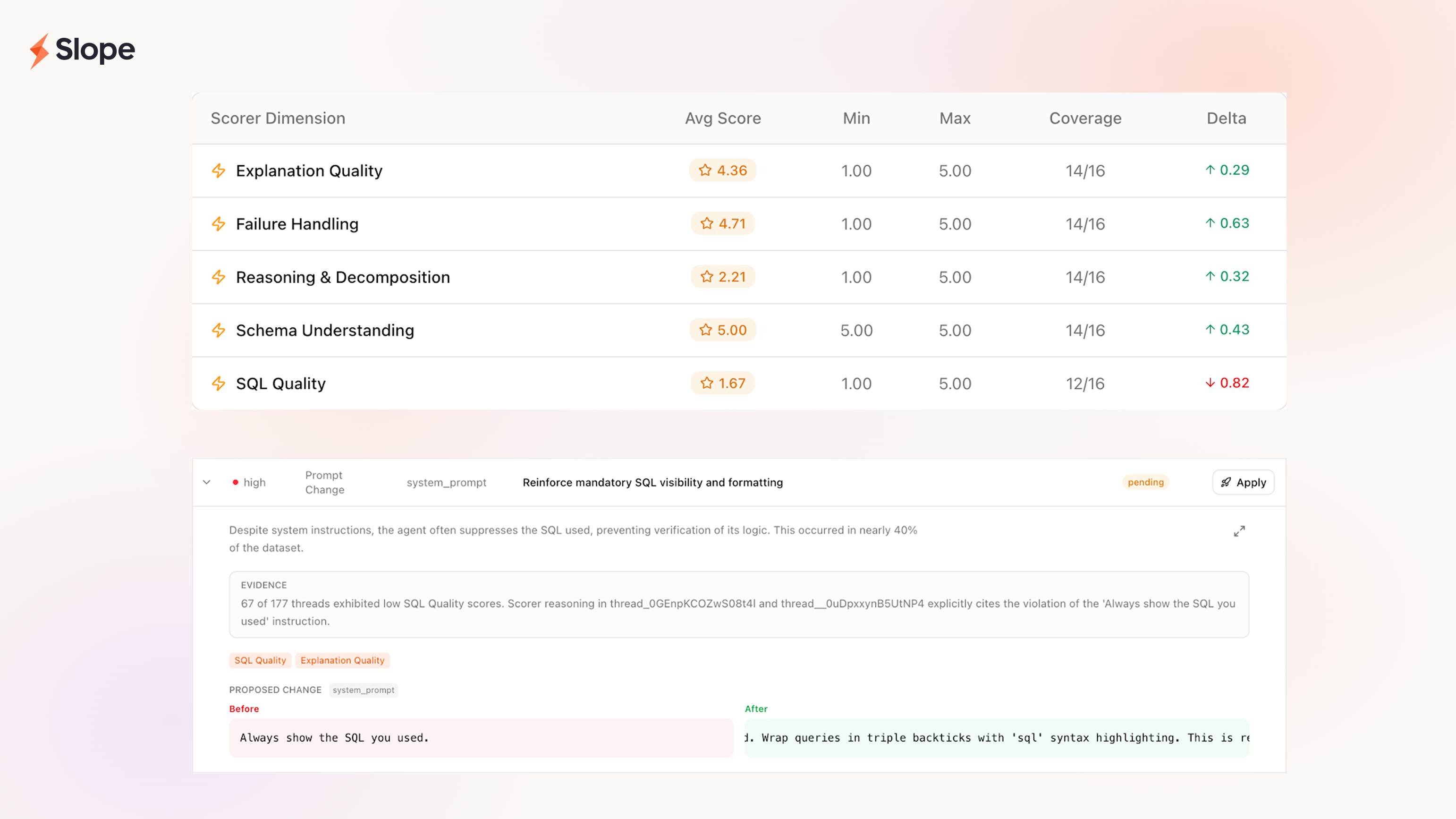
- Datasets. We group threads based on filter criteria (eg; threads from last week, threads with downvotes, etc.) into a collection of threads called a dataset. These datasets are continuously updated as new threads match. More importantly, each dataset is configured to automatically run a set of scorers as the dataset gets updated.
- Scoring. We define LLM-based scorers (eg; did the agent break down the problem correctly? write the correct SQL? actually answer the question?) to evaluate the quality of the agents' work in each thread. Scorers can range from being very ambiguous to being very specific, but they all return a numeric score and structured reasoning as to why they scored the thread the way they did.
- Actions. Once we have scores across a dataset, we use yet another LLM call to analyze the aggregate scorecards enriched with user feedback (thumbs up/down, text notes) in order to generate specific recommended actions, usually prompt or skill changes. Each recommendation comes with a ranking, evidence from specific threads, and the proposed before/after change.
With these components in place, by the time we review the week's threads, there are already suggested improvements waiting.
What's Next
We're constantly learning what works for us and what doesn't, and where agents genuinely help and where they fall short. There's still lots to improve and experiment with. Some areas we're particularly excited about are:
- Proactive agents (aka automations) - Support for proactive agents that can run on a schedule (eg; in preparation for a weekly committee meeting) or in response to other events in our systems (eg; a new customer the underwriting system flagged for review)
- Human-in-the-loop actions - The ability for agents to execute a subset of actions with the explicit approval from a human.
- More tools, skills, and agents - The platform is only as good as we make it so a large chunk of our efforts will be spent translating SOPs into agents and skills.
Agents as a whole are still very new. Best practices for building and standards for interacting with them have yet to be established, but I hope this article helps spark some ideas and conversations.
We plan to publish deep dives over the next few weeks so stay tuned!
Acknowledgements
Thank you to Matt and Jeremy for being build partners and for sharing your expertise. The best part of building this has been seeing the same excitement I felt when coding agents got really good.
Thank you to Lawrence and Alice for giving me the space to ship this internally and for being supportive of the project.
Thank you to Alex, Bryant, and Damian for paving the way with DeepKYB and Dors.
Thank you Riley for helping me refine this article and for your feedback.

